
by Luminița Ghervase — Published on August 18, 2025 — Reading time: 11 min
Article sections
» The era of open research data » Defining openness: what counts as open data » Opening the gates to Big Data » Risks, ethics, and the challenge of trust » Safeguarding science in an open world » Further reading and resources
The era of open research data
What happens when scientific data becomes wide open – accessible anytime, anywhere, in any form, for anyone, but with petabytes of raw data behind it? Nowadays, we want data – all sorts of data, to be publicly available to anyone. This has also extended to science data, where we presume that anyone working in science-related fields should be as open to the public as can be, by divulging their work and results without restraint, to any interested party.
Although the basis of open data theory had been laid about eighty years ago, with Merton’s sociological studies about the benefits of making research results freely available to all, the “open data” terminology appeared about thirty years back, embodying the idea of common good applied to knowledge, through the disclosure of geophysical and environmental data, for the complete, open exchange of scientific information between countries. Initially emerging within the scientific community, open data, open content, and open knowledge policies have since spread across a wide variety of areas. At the European level, the “open science” term was adopted ten years ago in the practices of the European Commission, following a public consultation, which indicated that European researchers were ready to implement the changes associated with open science.
Defining openness: what counts as open data
But what does “open data” actually mean? Several definitions have been offered for the term, by various entities dealing with open data, and they basically refer to the same thing. For instance, the Open Definition project has sketched the principles that define “openness” in the context of data and content. Those principles can be summed up into the following statement: “Open data and content can be freely used, modified, and shared by anyone for any purpose”. The Open Data Institute defines “open data” as “data that anyone can access, use or share”, while the Open Data Policy Lab states that “open data comprises data made accessible for reuse along a spectrum of openness and conditions for reuse”.
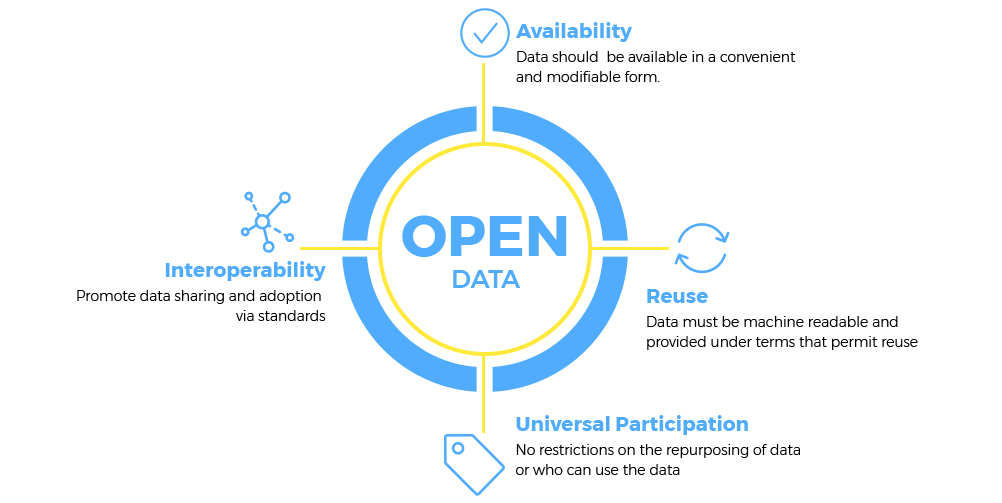
According to the Open Definition, any item or piece of knowledge being transferred, herein referred to as a “work” should comply with several requirements:
- must be provided in such a format that places no restrictions in use and processing;
- must be part of the public domain or provided under an open license;
- must be provided at no more than a reasonable one-time reproduction cost, and should be downloadable via the Internet without charge;
- must be provided in a form that can be processed by a computer and where the individual elements of the work can be easily accessed and modified;
A license defines the legal terms under which a “work” — such as a dataset, publication, or piece of software — is made available to others. In the context of open research data, a license is considered open when it grants broad freedoms to access, use, modify, and share the work without unnecessary restrictions. These freedoms are not arbitrary; they are defined by a clear set of criteria that ensure the work remains genuinely open to all, fostering transparency, collaboration, and innovation.
However, even open licenses can include specific requirements — such as attribution or maintaining the same license in derivative works — that supplement, rather than limit, these core freedoms. The table below outlines both the essential criteria for an open license and the common conditions that may apply alongside them.
| Must allow free use of the licensed work | May require attribution to contributors, rights holders, sponsors, and creators |
| Must allow any form of redistribution | May require modified versions to have a different name or version number |
| Must allow creation and distribution of derivative works | May require distributions to remain under the same or similar license |
| Must allow any part to be used, distributed, or modified separately | May require retention of copyright notices |
| Must allow distribution without restrictions | May require distributions to remain free of technical measures |
| Must not discriminate against persons or groups | May require modifiers to grant the public additional permissions |
| Rights must apply to all recipients | |
| Must allow use, redistribution, modification, and compilation for any purpose | |
| Must not impose fees, royalties, or other compensation | |
Opening the gates to Big Data
While openness promises global growth, the volume and diversity of scientific data raise unprecedented concerns on both technical and ethical levels. Research data represent any type of information resulting from the process of research or development, such as numbers, text, or a combination of both, generally considered a requirement by the scientific community to validate research findings, to enable analysis or support decision-making processes. If only a decade ago “big data” and “open data” were two different definitions, nowadays they often intertwine. In science, we are confronted not only with the sharing of data but with sharing a lot of data. The definition of “big data” is somewhat fluid, referring to datasets that exceed the computational or processing power, in a reasonable amount of time, of commonly used programs, and which require advanced storage solutions, standardization, and interoperability.

Going a step further, the most important aspects of big data have been defined as volume, velocity, and variety. Scientific experiments can yield terabytes, petabytes, or even zettabytes of data, as seen in astrophysical observations, geophysical information, or particle physics experiments, for instance. So, beyond sharing small-scale experiments and individual findings, we are sharing massive volumes of raw experimental results and processed data, with a global perspective of increasing the amount of data produced in the near future. This, in turn, brings along some major challenges, which are related, first of all, to storage – where do we store such volumes, how can we ensure their long-term preservation, and at what costs? Second, there is the problem of data manipulation, in terms of how we process this huge amount of data that is inter-correlated. Big data requires high-end, sophisticated equipment, with high computational power.
Another aspect to be considered is the peril of data misinterpretation due to confusion created by the lack of standardized language – that is why standard data formats, tools, and methodologies are required to ensure consistency across large datasets. However, at least at the European level, efforts in encouraging such standardized language have increased, as indicated by the most recent open data maturity reports. One other aspect to be considered takes into account the ethics of it all – how do we ensure that personal or sensitive information is kept safe?
Risks, ethics, and the challenge of trust
The main goal of openness in research data is to strengthen collaboration between researchers and reduce the global waste of resources while increasing transparency and reproducibility of results, and, finally, increasing the adaptability of research to societal challenges. While open data policies encourage the use of available resources instead of starting from scratch, the question arises of whether it is ethical or not, or to what extent, to allow not only the free use and sharing of data but also to modify such data. Apart from obvious security concerns and the possibility of altered reality, the permission to modify freely available data can be dangerous for a variety of reasons. Modifying scientific data can lead to great progress, by building upon an existing structure, but it can, however, also lead to misinterpretation and misinformation.
How can we make sure that altered data are highlighted and eliminated or, at the very least, marked as wrongful? Especially given that the use of false or erroneous data can lead to flawed conclusions, such as, for instance, misinterpretation of freely available satellite data which has led to the erroneous classification of forests as croplands, or wrongful data manipulation that has led to critical errors in justifying controversial science-based economic policies. These can eventually diminish the audience’s trust in scientific research. This is why transparency and traceability are amongst the most important issues in open data policies, making it imperative for any alterations to original datasets to be flagged accordingly, and properly linked to the original datasets, given that the original datasets were made available with the proper persistent identifiers and metadata, under an open license. Of course, another vital aspect is honesty and a good work ethic, which, combined, can warrant that all data processing and further use are done in the best possible way.
Safeguarding science in an open world
One way to tackle these issues is through standardized validation mechanisms, such as blockchain-based verification or AI-driven anomaly detection, which can ensure the trustworthiness and utility of shared information. Guided by, amongst others, the principles of epistemic validity and ontological integrity, academic validation mechanisms are intended to ensure that reality is represented as accurately as possible, that reliable knowledge is shared, and that potential discrepancies between reality and data representations are rigorously identified. Blockchain-based verification offers a secure platform for data exchange, ensuring the integrity of data, and enhancing transparency and trust, while AI-driven anomaly detection can identify outliers, and inconsistencies in the datasets, and flag suspicious trends while maintaining reliability across research fields.
So, as we embrace the trend of openness in research data, we are confronted with the critical issue of preserving scientific integrity whilst opening research results to the more- or less-prepared public. All parties involved, from researchers to policy-makers and even citizens should advocate for validation, transparency, and standardization in open data management, to ensure trustworthiness and global accessibility.
Further reading and resources
Badshah, A. et al. (2024). Big data applications: overview, challenges and future. Artificial Intelligence Review 57, 290. https://doi.org/10.1007/s10462-024-10938-5
Borgman, C.L. (2012). The conundrum of sharing research data. Journal of the American Society for Information Science and Technology 63(6), 1059-1078. https://doi.org/10.1002/asi.22634
Borgman, C.L. (2017). Big Data, Little Data, No Data: Scholarship in the Networked World. MIT Press.
Burgelman, J.C. et al. (2019) Open Science, Open Data, and Open Scholarship: European Policies to Make Science Fit for the Twenty-First Century. Frontiers in Big Data 2, 43. https://doi.org/10.3389/fdata.2019.00043
Chen, J. et al., (2013). Big data challenge: A data management perspective. Frontiers of Computer Science 7, 157-164. https://doi.org/10.1007/s11704-013-3903-7
Chignard, S. (2013, Mar 29). A brief history of open data. Paris Tech Review. Available online: https://www.paristechreview.com/2013/03/29/brief-history-open-data/
Dodds, L. (2016, Dec 26). How to write a good open data policy. Open Data Institute. Available online: https://theodi.org/insights/guides/how-to-write-a-good-open-data-policy/
Gurung, I. et al. (2023). Exploring Blockchain to Support Open Science Practices. In IGARSS 2023 – 2023 IEEE International Geoscience and Remote Sensing Symposium, IEEE, pp: 1205-108. https://doi.org/10.1109/IGARSS52108.2023.10283181
Hey, A.J.G., and Trefethen, A. (2003). The data deluge: An e-science perspective. In Berman, F., Fox, G., and Hey, A.J.G. (eds). Grid computing: Making the global infrastructure a reality. Chichester: Wiley.
Hodge, V. J., and Austin, L. (2004). A Survey of Outlier Detection Methodologies. Artificial Intelligence Review 22, 85-126. https://doi.org/10.1023/B:AIRE.0000045502.10941.a9
Jean-Quartier, C. et al. (2024). Fostering Open Data Practices in Research-Performing Organizations. Publications 12(2), 15. https://doi.org/10.3390/publications12020015
Marchioro, N.G. et al. (2025). Trustworthy Provenance for Big Data Science: A Modular Architecture Leveraging Blockchain in Federated Settings. arXiv. https://doi.org/10.48550/arXiv.2505.24675
Matter, Y. (2023). Big Data Analytics. A Guide to Data Science Practitioners Making the Transition to Big Data, 1st ed., Chapman and Hall/CRC.
Maurya, C.K. (2022). Anomaly Detection in Big Data. arXiv. http://arxiv.org/abs/2203.01684
Merton, R. K. (1942). The Normative Structure of Science, University of Chicago Press.
Miller, G., and Spiegel, E. (2025). Guidelines for Research Data Integrity (GRDI). Scientific Data 12, 95. https://doi.org/10.1038/s41597-024-04312-x
Nowogrodzki, J. (2020, Jan 1). Eleven tips for working with large data sets. Nature 577, 439-440. https://doi.org/10.1038/d41586-020-00062-z
Open Data Institute (2026, Sep 2). What is open data? Available online: https://theodi.org/news-and-events/blog/what-is-open-data/
Osarenren, P.A. (2024, Sep 24). A Comprehensive Definition of Data Provenance. Acceldata. Available online: https://www.acceldata.io/blog/data-provenance
Page, M., Behrooz, A., and Moro, M. (2025). 2024 Open Data Maturity Report. Publications Office of the European Union. Ailbale online: https://data.europa.eu/sites/default/files/odm2024_full_report.pdf
Publications Office of the European Union (2024, Feb 20). Open Data Maturity 2023 – Best practices across Europe. YouTube. https://www.youtube.com/watch?v=rEFfp1OcBeY
Sustainability Directory (2025, Apr 9). Open Data Validation. Available online: https://prism.sustainability-directory.com/term/open-data-validation/
X. Ye (2018). Open Data and Open Source GIS. In Huang, B. (ed). Comprehensive Geographic Information Systems. Elsevier, pp. 42-49. https://doi.org/10.1016/B978-0-12-409548-9.09592-0
Xu, X. et al. (2024). Comparative Validation and Misclassification Diagnosis of 30-Meter Land Cover Datasets in China. Remote Sensing 16(22), 4330. https://doi.org/10.3390/rs16224330

How to cite this resource
Ghervase, L. (2025). The growing trend of open research data policies: big data, big problems? INFRA-ART Blog