
by Ioana Maria Cortea — Published on July 30, 2025 — Reading time: 12 min
Part of the INFRA-ART FAIR Journey article series
Article sections
» From principles to practice: the role of FAIR assessment tools » Understanding FAIRsFAIR assessment metrics » Choosing the right FAIR assessment tool » Common pitfalls in FAIR assessments » Case study: assessing INFRA-ART with the F-UJI tool » Further reading and resources

From principles to practice: the role of FAIR assessment tools
In today’s science and tech landscape, sharing data isn’t enough—it needs to be FAIR. The FAIR principles are quickly becoming a cornerstone of modern research, ensuring that data can be discovered, understood, and reused by others—and increasingly, by machines. But here’s the challenge: how do you know if your data is actually FAIR? This post explores the growing ecosystem of FAIR assessment tools: what they are, how they work, and how they’re shaping the future of responsible, reusable data.
Measuring FAIRness is essential is helping researchers and institutions advance toward concrete improvements aligned with the open science movement. During the initial phase of EOSC implementation (2018–2020), various projects and initiatives focused on creating methods to assess both the FAIRness of research data and the capacity of organizations and services to enable FAIR practices. These efforts led to the development of a range of tools and resources aimed at supporting the practical adoption of FAIR principles across key stakeholder groups.
Under initiatives like FAIRsFAIR, a diverse portfolio of FAIR assessment tools has been developed—each tailored to different object types such as datasets, semantic artefacts, and software, as well as a variety of research contexts. As EOSC enters its next phase of development, a new wave of Horizon Europe-funded projects is building on earlier efforts to refine and expand the tools and methods available for implementing the FAIR principles. These resources are essential for translating FAIR from theory into practice, but with so many resources available, it can be challenging for researchers, data stewards, and institutions to know which tool best fits their needs. To address this, the FAIR Implementation Catalogue has been created as a central hub of trusted FAIR-enabling tools and resources. More than just a list, it’s a curated, open-access platform that helps users identify the right solutions for their specific use cases, object types, and technical contexts. The catalogue goes beyond tools—it also includes guidelines, training materials, and interoperability frameworks, creating a one-stop ecosystem for research-performing organizations and service providers seeking to integrate FAIR implementation into their workflows, platforms, or data policies.

Understanding FAIRsFAIR assessment metrics
FAIR assessment tools provide structured, often automated, ways to assess how well a dataset, ontology, or other digital object aligns with the FAIR principles. These tools translate intention into action by making data quality visible to funders, journals, and collaborators. Through objective, transparent evaluations, they help researchers and institutions iteratively improve data management, build trust in shared outputs, and prepare data for long-term reuse. One of the key contributions to the FAIR assessment landscape comes from the FAIRsFAIR project, which developed a comprehensive set of metrics based on indicators proposed by the RDA FAIR Data Maturity Model Working Group. Refined through FAIR-IMPACT, these metrics offer a standardized, domain-agnostic framework for assessing how well digital objects — such as datasets and metadata — comply with the FAIR principles.
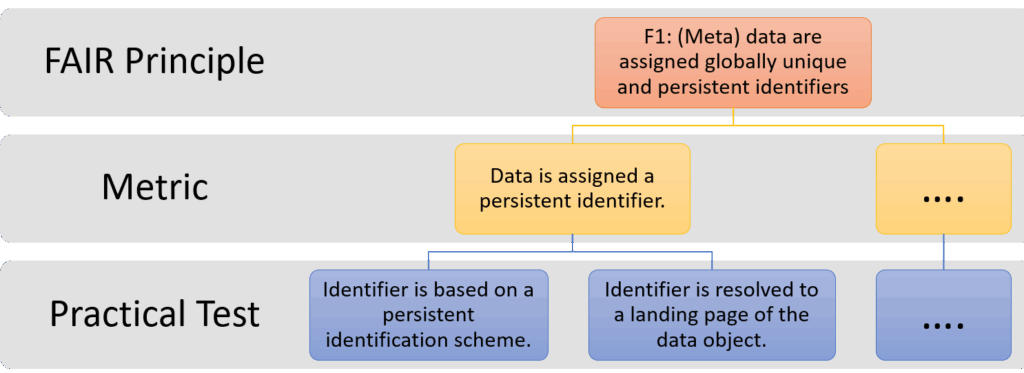
Rather than offering broad guidelines, the FAIRsFAIR metrics break each FAIR principle into clear, testable indicators such as: the use of persistent identifiers (PIDs); availability of machine-readable metadata; presence of a clear license; the use of community standards and vocabularies; etc. Each metric is mapped to specific FAIR principles and CoreTrustSeal requirements, supporting objective and reproducible evaluations. With the release of version 0.8, the metrics have been substantially revised to reflect feedback from the user community and findings from multiple studies comparing FAIRsFAIR with other assessment approaches.
The FAIRsFAIR Data Object Assessment Metrics act as a foundation for many current assessment tools, allowing for transparent scoring, comparison, and iterative improvement. Importantly, they also serve as a common reference point for developers, repository managers, and data stewards working to align with FAIR requirements. While these metrics offer a powerful framework for evaluating FAIRness, it’s important to remember that FAIR assessment doesn’t stop at the digital object itself. The broader ecosystem of FAIR-enabling services—including repositories, registries, and infrastructures—plays a critical role in ensuring that data remains FAIR over time. Additionally, although many metrics can be tested automatically, not all aspects of FAIRness are machine-assessable. Qualities like metadata richness, relevance, and contextual accuracy often require human interpretation and domain expertise.
Choosing the right FAIR assessment tool
Not all FAIR tools are created equal. Depending on your role and needs, different tools will be more appropriate. This section presents a selection of FAIR assessment tools, chosen to highlight the latest developments in the field and to support the diverse needs of scientific communities, research-performing organizations, and digital infrastructures. Whether you’re managing a repository or designing a data platform, these tools help you understand where you stand and where to go next. They provide valuable insights that guide improvements, making FAIR adoption a more transparent and achievable process. Collectively, these tools support researchers, data stewards, and institutions in evaluating and enhancing the FAIRness of their data, ultimately promoting stronger, more reusable data management practices across the research ecosystem.
FAIR-Aware (FAIR Data Self-Assessment Tool)

Type: Self-assessment and educational tool.
Audience: Researchers, data creators, early-career scientists.
Purpose: Helps users understand how their data practices align with the FAIR principles before data is shared or published.
Highlights:
- Presents 10 practical questions covering key FAIR aspects (e.g., metadata, licensing, accessibility).
- Provides instant feedback and tailored recommendations to improve FAIR compliance.
- Designed to raise awareness and build knowledge—not to assign a FAIR score.
- Web-based, intuitive, and free to use; no login required.
- Ideal for training, onboarding, and promoting responsible data sharing across disciplines.
F-UJI (Automated FAIR Data Assessment Tool)
Type: Automated FAIRness evaluator.
Audience: Data stewards, repository managers, researchers.
Purpose: Automatically assesses the FAIRness of digital objects, particularly research datasets, using metadata and persistent identifiers.
Highlights:
- Based on 17 FAIR principles, with 16 metrics implemented from the RDA FAIR Data Maturity Model.
- Evaluates key aspects such as machine-readability, license clarity, and metadata richness.
- Outputs a detailed breakdown and overall score via a user-friendly interface.
- Designed for interoperability with repositories and research infrastructures.
- Open-source and freely accessible through the F-UJI web service or for local deployment.
O’FAIRe (Ontology FAIRness Evaluator)

Type: Automated FAIRness assessment tool for ontologies and semantic artefacts.
Audience: Data steward, repository or service manager.
Purpose: O’FAIRe is designed to automatically assess the FAIRness of semantic resources, such as ontologies, terminologies, taxonomies, thesauri, vocabularies, metadata schemas, and standards. It evaluates how well these resources adhere to the 15 FAIR principles by analyzing their metadata.
Highlights:
- Implements 61 assessment questions, with approximately 80% based on resource metadata descriptions.
- Provides both global and detailed normalized scores against the FAIR principles.
- Visualizes results through user-friendly interfaces, including the “FAIRness wheel,” to aid users in understanding and improving their resources’ FAIRness.
- Currently implemented in multiple public ontology repositories, such as AgroPortal, EcoPortal, EarthPortal, BiodivPortal, and IndustryPortal.
- Open-source and deployable as a web service compatible with OntoPortal-based repositories.
FOOPS! (Ontology Pitfall Scanner for FAIR)

Type: FAIRness validator for semantic artefacts.
Audience: Ontology developers, semantic web practitioners.
Purpose: Assesses the FAIRness of ontologies and vocabularies (OWL or SKOS) by checking compliance with best practices for web publication.
Highlights:
- Designed for semantic artefacts across any domain.
- Requires no specific expertise to use.
- Validates against FAIR-focused criteria from key community publications and recommendations.
- Supports institutions (e.g., universities) and international infrastructures aiming to improve semantic resource quality.
| Tool | Type of resource/tool | Target audience | Developed by | Source code |
| FAIR-Aware | self-assessment and educational tool | researchers, data creators, early-career scientists. | FAIRsFAIR project | https://github.com/FAIRsFAIR/fair-aware |
| F-UJI | automated fairness evaluator of research data objects | data stewards, repository managers, researchers | FAIRsFAIR project | https://github.com/pangaea-data-publisher/fuji |
| O’FAIRe | automated fairness assessment tool for ontologies and semantic artefacts | data steward, repository or service manager | AgroPortal project, supported by University of Montpellier and INRAE | https://github.com/agroportal/fairness |
| FOOPS! | automated fairness evaluator for ontologies | ontology or vocabulary developer or publisher | Ontology Engineering Group – Universidad Politécnica de Madrid | https://github.com/oeg-upm/fair_ontologies |
| Tool | Type | Notable Feature |
| AutoFAIR | Automated | Bioinformatics-focused; supports datasets, tools, and workflows |
| FAIRdat | Manual | Survey-based self-assessment for datasets |
| FAIRshake | Customizable | Supports community-defined metrics and flexible rubrics |
| FAIR EVA | Modular | Evaluator, Validator, and Advisor components for flexible use |
| FAIR Evaluator | Automated | Implements FAIR Metrics WG tests; community-governed |
| FAIR-Checker | Automated | Uses knowledge graphs and semantic web standards |
| FAIREST | Manual | Assesses research repositories, including organizational aspects |
| FAIROs | Automated | Evaluates FAIRness of RO-Crate-based digital research objects |
| HowFAIRis | Automated | Assesses FAIRness of research software using Git repositories |
| OpenAIRE Validator | Automated | Evaluates repository FAIR compliance with OpenAIRE standards |
| SATIFYD | Manual | Assesses discipline-specific data practices (e.g., nanosafety) |
Common pitfalls in FAIR assessments
While FAIR assessment tools help make the FAIR principles more actionable, many users run into recurring issues—especially when relying solely on automated evaluations. A recent study by Candela et al. (2024) highlights a key reality: FAIR assessment is complex and context-dependent. While automated tools like F-UJI offer structure and consistency, they often reflect the specific interpretations of their developers. Many metrics show gaps between their stated purpose and what they actually test, especially around concepts like openness or metadata quality.
Understanding some common pitfalls in FAIR assessment can help you interpret results more effectively and take meaningful steps toward improvement. Here’s what to watch out for:
- Openness ≠ FAIRness: FAIR doesn’t require data to be open—just clearly documented. Restricted access is fine if conditions are transparent.
- Missing or unclear licenses: One of the most common errors. Without a standard, machine-readable license, reuse becomes legally ambiguous.
- Weak metadata structure: Vague or unstructured metadata—especially lacking schema.org or standard vocabularies—reduces machine readability.
- Non-resolvable or misconfigured identifiers: Including a DOI isn’t enough. It must resolve correctly, often via redirection.
- Overlooked protocol support: Metadata must be retrievable through standard, accessible protocols (e.g. HTTPS, OAI-PMH).
- Treating FAIR as a checkbox: FAIRness can degrade. Regular reassessment is essential—especially for long-term or widely reused data.
The key takeaway? Use FAIR tools as diagnostic aids, not just scoring systems—they help identify gaps and guide improvements that strengthen data visibility, trust, and long-term reusability.
Case study: assessing INFRA-ART with the F-UJI tool
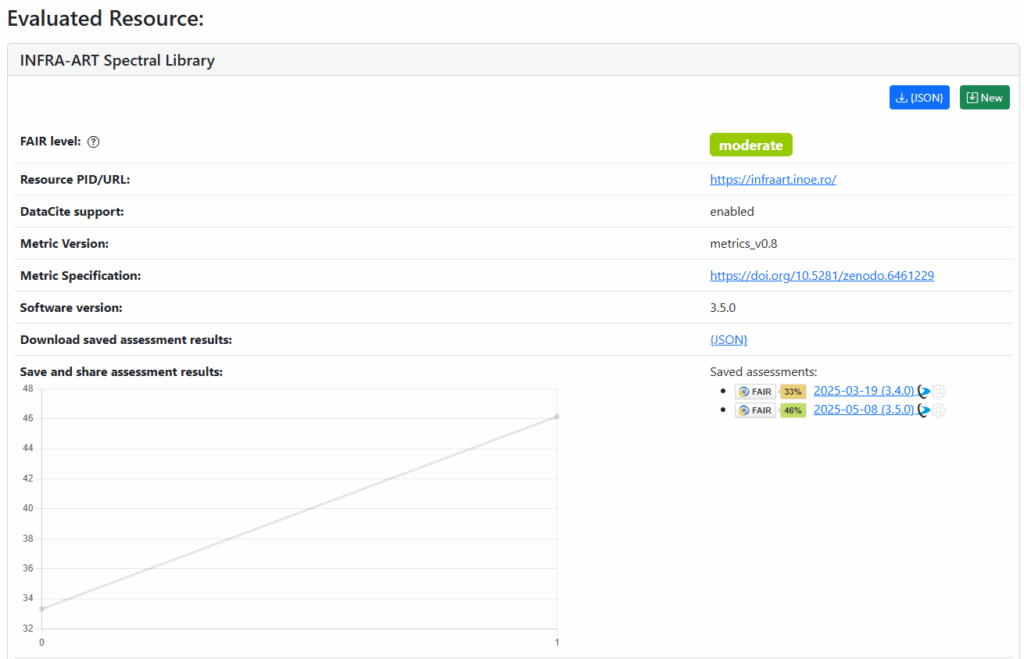
To understand how automated FAIR assessments work in practice, we tested the F-UJI tool to the INFRA-ART database. The F-UJI tool provides a web interface where users can enter a dataset’s URL or persistent identifier (e.g., DOI). It then evaluates the object against a set of machine-actionable metrics aligned with version 0.8 of the FAIRsFAIR Data Object Assessment Metrics. The results are presented as a detailed FAIRness report, covering findability, accessibility, interoperability, and reusability — each scored and color-coded for clarity.
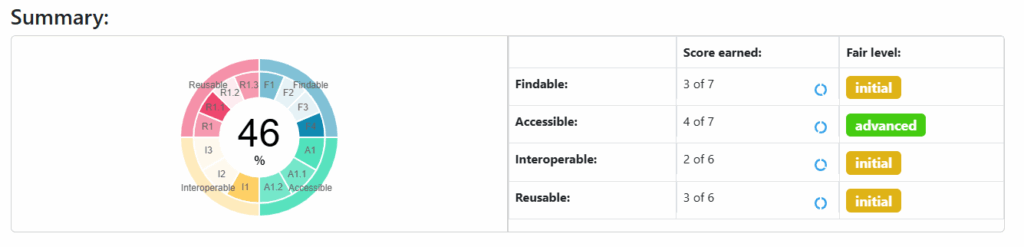
The INFRA-ART database received an overall FAIR level score of 46%, placing it in the moderate range. The strongest performance was in Accessibility, with 4 out of 7 metrics achieved. This indicates that both metadata and data are retrievable through standard protocols without access restrictions—a critical baseline for FAIR compliance. The tool also delivered metric-by-metric feedback and actionable suggestions, offering a clear roadmap for improving weaker areas like Interoperability and Reusability, where missing semantic standards and unclear licensing limited the score.


Further reading and resources
Akerman, V. et al. (2021). FAIR-Aware: Assess Your Knowledge of FAIR (v1.0.1). Zenodo. https://doi.org/10.5281/zenodo.5084861
Amdouni, E. et al. (2022). O’FAIRe makes you an offer: Metadata-based Automatic FAIRness Assessment for Ontologies and Semantic Resources. International Journal of Metadata, Semantics and Ontologies, 16(1): 16-46. https://doi.org/10.1504/IJMSO.2022.131133
Candela, L. et al. (2024) The FAIR Assessment Conundrum: Reflections on Tools and Metrics. Data Science Journal, 23: 33. https://doi.org/10.5334/dsj2024-033
CoreTrustSeal Standards and Certification Board. (2022). CoreTrustSeal Requirements 2023-2025 (V01.00). Zenodo. https://doi.org/10.5281/zenodo.7051012
de Bruin, T. et al. (2020). Do I-PASS for FAIR. A self assessment tool to measure the FAIR-ness of an organization (Version 1). Zenodo. https://doi.org/10.5281/zenodo.4080867
Devaraju, A., and Herterich, P. (2020). D4.1 Draft Recommendations on Requirements for Fair Datasets in Certified Repositories (1.0). Zenodo. https://doi.org/10.5281/zenodo.5362222
Devaraju, A., and Huber, R. (2025). F-UJI – An Automated FAIR Data Assessment Tool (v3.5.0). Zenodo. https://doi.org/10.5281/zenodo.15118508
Devaraju, A., et al. (2022). FAIRsFAIR Data Object Assessment Metrics (0.5). Zenodo. https://doi.org/10.5281/zenodo.6461229
FAIR Data Maturity Model Working Group. (2020). FAIR Data Maturity Model. Specification and Guidelines (1.0). Zenodo. https://doi.org/10.15497/rda00050
FAIR Implementation Catalogue, https://catalogue.fair-impact.eu/
Garijo, D. et al. (2021). “FOOPS!: An Ontology Pitfall Scanner for the FAIR principles.” In ISWC (Posters/Demos/Industry). https://foops.linkeddata.es/assets/iswc_2021_demo.pdf
Garijo, D., and Poveda-Villalón, M. (2020). Best Practices for Implementing FAIR Vocabularies and Ontologies on the Web, arXiv:2003.13084. https://doi.org/10.48550/arXiv.2003.13084
Huber, R. (2025). FAIRsFAIR Data Object Assessment Metrics (0.8). Zenodo. https://doi.org/10.5281/zenodo.15045911
Hugo, W., et al. (2020). D2.5 FAIR Semantics Recommendations Second Iteration (1.0 DRAFT). Zenodo. https://doi.org/10.5281/zenodo.4314321
L’Hours, H. et al. (2022). Report on a maturity model towards FAIR data in FAIR repositories (D4.6) (2.0 DRAFT). Zenodo. https://doi.org/10.5281/zenodo.6421728
Poveda-Villalón, et al. (2020). Coming to Terms with FAIR Ontologies. In: Keet, C.M., Dumontier, M. (eds) Knowledge Engineering and Knowledge Management. EKAW 2020. Lecture Notes in Computer Science, vol 12387. Springer, Cham. https://doi.org/10.1007/978-3-030-61244-3_18
Tanderup, N., et al. (2024). M6.1 Outcome of testing components to achieve core technical & semantic interoperability in cross-domain use cases (1.0). Zenodo. https://doi.org/10.5281/zenodo.10940164
Wilkinson, M., et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data 3, 160018. https://doi.org/10.1038/sdata.2016.18

How to cite this resource
Cortea, I.M. (2025). Is your data FAIR? Tools that help you find out. INFRA-ART Blog. DOI: 10.5281/zenodo.16601172