
by Ioana Maria Cortea — Published on June 27, 2025 — Reading time: 11 min
Part of the INFRA-ART FAIR Journey article series
Article sections
» What is metadata and why is important? » Enabling FAIR with machine-readable metadata » Challenges in current metadata practices » Structuring metadata for interoperability and discovery » Making repositories transparent and trustworthy » FAIR-enabling the INFRA-ART Spectral Library » Further reading and resources
What is metadata and why is important?
Metadata—commonly described as “data about data”—is the structured information that makes datasets findable, understandable, and reusable. According to ISO 11179, metadata is defined as “descriptive data about an object”. This definition fits well with how metadata is used in the paper of Wilkinson et al. on FAIR Principles, where “data” refers broadly to any type of digital object—not just numbers or measurements, but also things like software, workflows, hardware designs, etc. In this broader view, metadata is any information that helps us find, understand, reuse, or evaluate a digital resource.
Sometimes, data and metadata are published together. Other times, they’re stored separately but linked through identifiers. And it’s common for a single digital object to have multiple types of metadata attached to it, each serving a different purpose. While many metadata systems and standards exist today, there are also well-established models that classify metadata into distinct types. For example, the National Information Standards Organization (NISO) classifies metadata as:
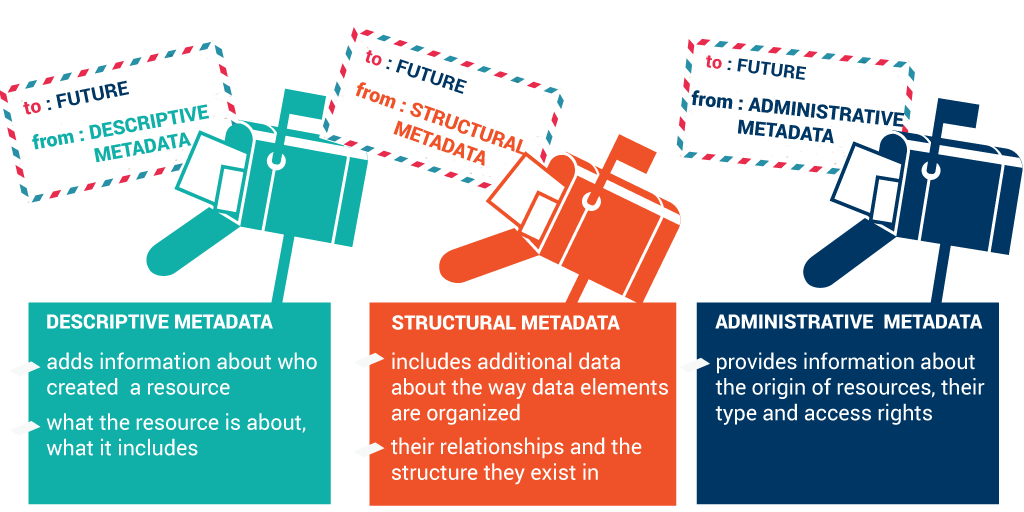
- Descriptive metadata (for finding or understanding a resource)
- Administrative metadata
- Technical metadata (for decoding and rendering files)
- Preservation metadata (long-term management of files)
- Rights metadata (intellectual property rights attached to content)
- Structural metadata (relationships between files or datasets)
- Markup languages (integrates metadata and flags for other structural or semantic features within content)
Enabling FAIR with machine-readable metadata
In a digital repository, metadata is essential for transforming raw data into a meaningful and usable resource. It plays several critical roles, including enabling the discovery and identification of resources, supporting digital object management, and facilitating navigation within large and complex datasets. Additionally, metadata allows institutions to maintain transparency and track the origin, usage, and evolution of research outputs over time.
To make data truly FAIR, repositories must not only manage high-quality metadata, but also expose that metadata in a way that is both transparent and machine-readable. With machine-readable metadata in place, systems can:
- Automatically discover datasets through structured web crawling.
- Consistently index repository content, even across different platforms.
- Link related datasets, tools, and publications, creating a connected web of research resources.
In practice, this transforms a static webpage into a rich, interoperable data node that machines can navigate, interpret, and reuse—crucial for modern research workflows and digital preservation. At the core of this effort is the use of standardized metadata schemas, ontologies, and controlled vocabularies, which form the structural backbone of interoperability. In line with the FAIR principles, interoperability refers to the need for research data to be integrated with other datasets. Additionally, it emphasizes that data must be compatible with applications and workflows used for analysis, storage, and processing. The following principles are proposed:
- I1. (Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
- I2. (Meta)data use vocabularies that follow FAIR principles.
- I3. (Meta)data include qualified references to other (meta)data.
Challenges in current metadata practices
The ability to find and evaluate digital objects and repositories relies on clear identification and effective discovery mechanisms. In practice, however, many digital objects remain difficult to locate and reuse, which negatively impacts the quality and efficiency of research.
A review of the CORE (COnnecting REpositories) collection, containing over 123 million metadata records, revealed widespread issues in metadata quality across repositories and data archives. These problems stem primarily from outdated technologies, inconsistent metadata practices, and poor interoperability with modern systems such as search engines, semantic web tools, and FAIR infrastructures. According to the analysis carried out by the EOSC Executive Board Working Groups FAIR and Architecture the key shortcomings include:
- Inconsistent metadata profiles caused by software updates without backward compatibility or mapping between profile versions.
- Low-quality metadata transformations when adapting repository metadata for aggregators or search engines.
- File format issues, with some requiring obsolete or proprietary software for access.
- Lack of structured data types, resulting in free-text entries for dates, numbers, and subjects—often without language tagging.
- Minimal use of controlled vocabularies, versioning, or semantic standards; many repositories use custom vocabularies that cannot be easily mapped.
- Absence of authority control for names, affiliations, and projects.
- Broken or missing persistent links, unclear access conditions, missing provenance, and undefined usage licenses.
- Metadata duplication, especially between repositories and publishers, due to uncontrolled input and inconsistent metadata.
- Incomplete citation metadata, lacking persistent identifiers, author details, or publication information.
Addressing these metadata shortcomings requires more than just technical fixes—it calls for a shared understanding of how metadata should be structured, maintained, and aligned with community standards. Several international initiatives, such as those led by the Research Data Alliance (RDA), provide practical guidelines and principles to improve metadata granularity, semantic richness, and interoperability. The following section explores how these recommendations help create metadata that is both machine-actionable and trustworthy.
Structuring metadata for interoperability and discovery
RDA provides global guidelines and recommendations on how to structure metadata for maximum usability and trust. The RDA Metadata Interest Group has outlined five key metadata principles:
- The only difference between metadata and data is the mode of use.
- Metadata is not just for data, it is also for users, software services, computing resources.
- Metadata is not just for description and discovery; it is also for contextualization (relevance, quality, restrictions) and for coupling users, software, and computing resources to data (to provide a Virtual Research Environment).
- Metadata must be machine-understandable as well as human-understandable for autonomicity (formalism).
- Management (meta)data is also relevant (research proposal, funding, project information, research outputs, outcomes, impact…).
Furthermore, the Ten Principles for Dataset Discoverability developed by the RDA’s Data Discovery Paradigms Interest Group, emphasize that metadata should be published in machine-readable formats, should be enriched with linked vocabularies and persistent identifiers, indexed at multiple levels of granularity, and designed to support interdisciplinary search through mappings between domain-specific vocabularies.
To put these principles into practice, researchers, data curators, and repository managers rely on a combination of controlled vocabularies and structured metadata standards. Controlled vocabularies ensure consistency and clarity in how concepts are described across datasets, while metadata schemas provide the formal framework needed to organize, represent, and share information in a standardized way. Together, they enable digital objects to be precisely described, meaningfully linked, and reliably interpreted by both humans and machines.
According to current best practices, controlled vocabularies should be published under an open license and operated or maintained by a recognized standards organization or other trusted entity. They must be properly documented and provide labels in multiple languages. The vocabularies should include a relatively small set of broadly applicable terms that support the classification of a wide range of resources. Each term should be identified by a URI that resolves to relevant documentation, and the vocabulary must have clearly defined policies for persistence and versioning.
In parallel, metadata standards define the structural templates and descriptive elements used to implement these vocabularies within repository systems. Metadata records for digital objects stored in repositories and data archives are expressed using a variety of standards, profiles, and schemas. According to re3data.org, the most commonly used metadata formats include Dublin Core, the DataCite Metadata Schema, DDI (Data Documentation Initiative), ISO 19115, OAI-ORE (Open Archives Initiative Object Reuse and Exchange), and FGDC/CSDGM (Federal Geographic Data Committee Content Standard for Digital Geospatial Metadata).
Making repositories transparent and trustworthy
Transparency and evidence of trustworthiness are essential. End users rely on clear, visible metadata to evaluate the quality of datasets within a repository and make informed reuse decisions. While definitions of “trustworthiness” continue to evolve, exposing repository-level metadata is a concrete way to demonstrate commitment to FAIR and responsible data stewardship.
A clear, up-to-date description of a research data repository is essential for users to discover it, understand its purpose and policies, and assess its suitability. However, many repositories lack adequate, accessible, and machine-readable descriptions, hindering interoperability and integration with other systems. This makes comparison and discovery difficult, especially when information is hidden behind authentication or scattered across documents. Well-described repositories benefit a wide range of stakeholders (researchers, repository developers, funders) by improving discoverability and usability.
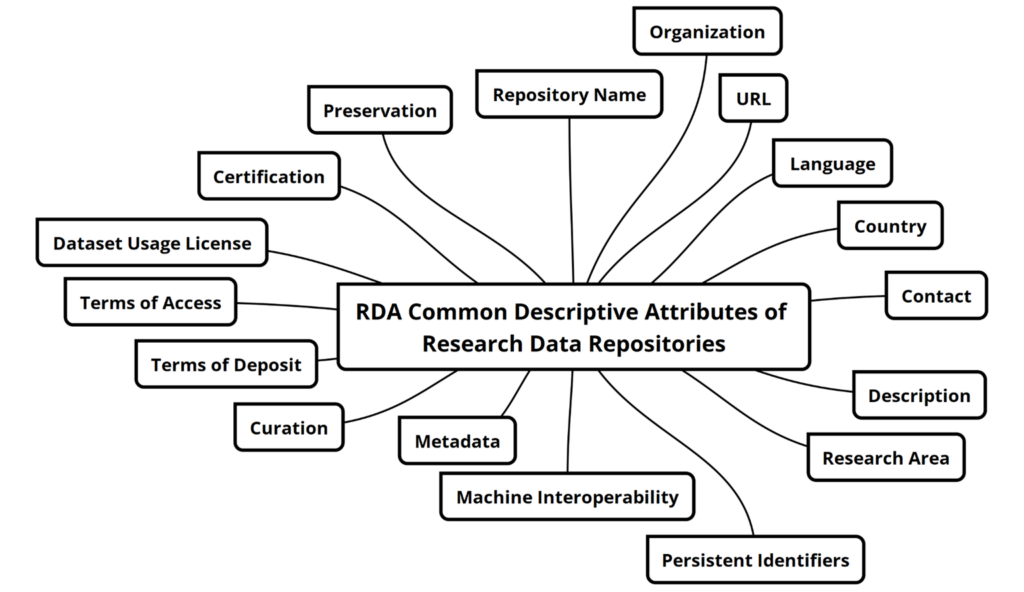
RDA outlines a set of common descriptive attributes of research data repositories that can improve discovery, interoperability, and trust. These include:
- Basic identification and operational context: Repository Name, URL, Country, Language, Organization, Contact, and Description.
- Technical and content-based descriptors that support discoverability and machine-actionability: Research Area, Persistent Identifiers, Metadata Standards, and Machine Interoperability.
- Policies and services that inform users about data submission, access, reuse, and value-added support: Curation, Terms of Deposit, Terms of Access, and Dataset Use License:
- Indicators of long-term reliability and repository trustworthiness: Certification and Preservation.
These principles and attributes are increasingly being put into practice to make repositories more transparent and better aligned with the FAIR principles. The following example from the INFRA-ART Spectral Library illustrates how we applied these recommendations in our own context, with the support of targeted tools and guidance from the FAIR-IMPACT project.
FAIR-enabling the INFRA-ART Spectral Library
FAIR-IMPACT is an EU-funded project advancing FAIR solutions across the European Open Science Cloud (EOSC). To help foster a FAIR ecosystem, FAIR-IMPACT supports key stakeholder groups to begin or progress their FAIR-enabling journeys via several mechanisms: support programs providing guidance and one-to-one support; cascading grants to enable testing of specific tools, approaches, and methods; and open FAIR implementation workshops.
Under route 2, support action #3 (Testing the trustworthy and FAIR-enabling repositories prototype), FAIR-IMPACT provided participants with access to a prototype tool designed to expose relevant machine-actionable metadata at the organizational and object level. The National Institute for Research and Development in Optoelectronics – INOE 2000 participated in this support action to enhance the FAIR-enabling capabilities of the INFRA-ART Spectral Library. At the outset, the repository lacked machine-readable metadata, limiting its discoverability and integration into broader research infrastructures.
Guided by FAIR-IMPACT’s prototype and guidelines, we:
- Conducted a self-assessment to identify gaps in our metadata and transparency.
- Reorganized our website and expanded documentation with clear information about data deposit policies, data access, and data curation.
- Implemented machine-actionable metadata using DCAT and schema.org in our homepage HTML.
- Used signposting to help external systems harvest our metadata.
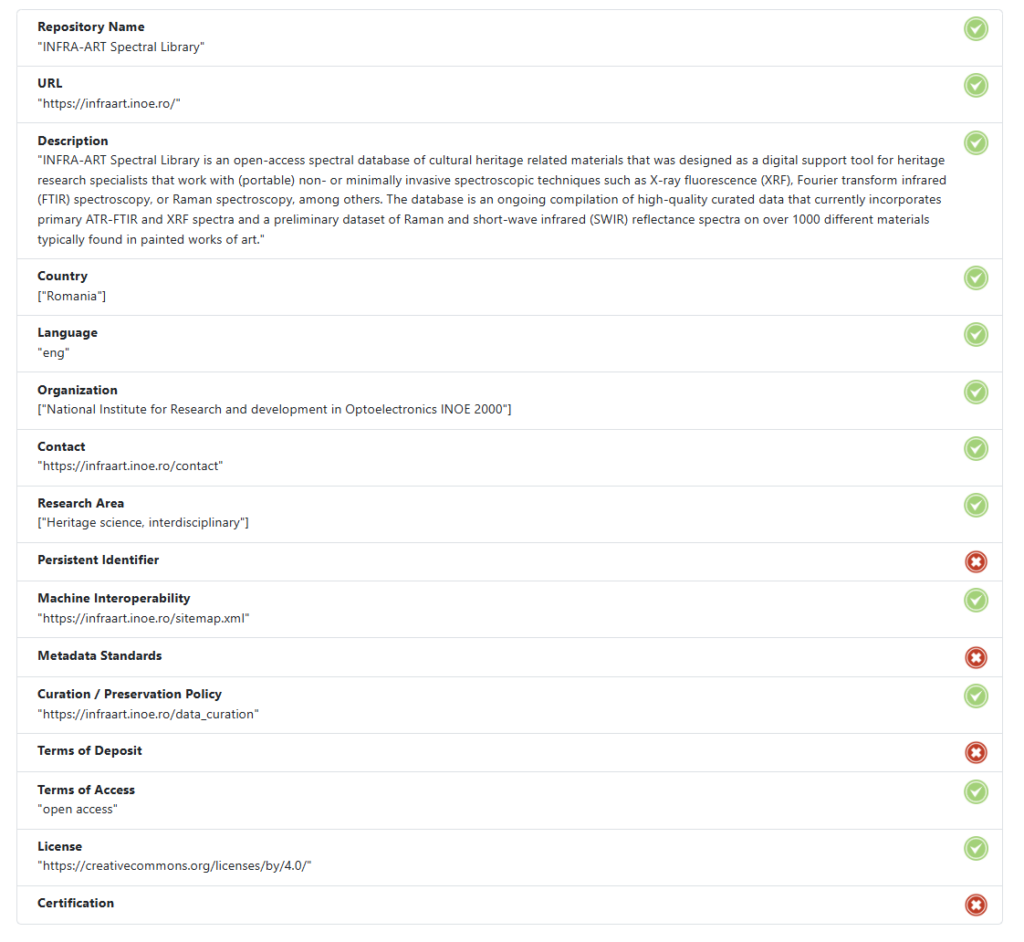
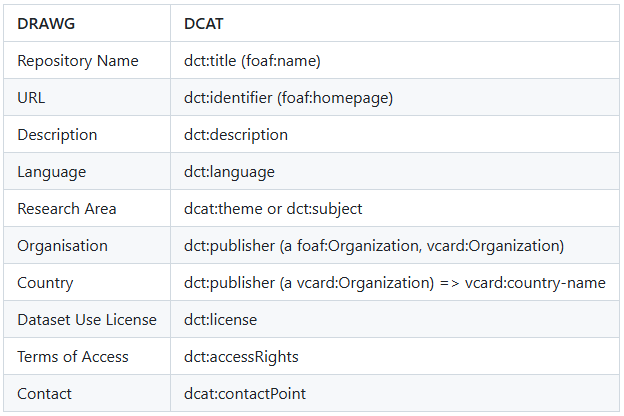
This process led to a substantial improvement in our FAIR metrics—achieving an initial FAIR level score of 33%, which we subsequently improved to 46%, as measured by F-UJI —and marked an important step toward aligning with EOSC guidelines.
You can read our full implementation story via the FAIR-IMPACT shared lessons on zenodo.
Further reading and resources
Cortea, I.M. (2025). Improving the findability, interoperability, and trustworthiness of the INFRA-ART Spectral Library – a dedicated data service for the heritage science domain. Zenodo. https://doi.org/10.5281/zenodo.15756790
Devaraju, A., and Huber, R. (2025). F-UJI – An Automated FAIR Data Assessment Tool (v3.5.0). Zenodo. https://doi.org/10.5281/zenodo.15118508
Documentary Heritage and Preservation Services for New York (2019, Feb 28). Metadata Matters: The Basics. YouTube. https://www.youtube.com/watch?v=OKSuBB0xRmY
European Commission: Directorate-General for Research and Innovation, Turning FAIR into reality – Final report and action plan from the European Commission expert group on FAIR data, Publications Office, 2018. https://data.europa.eu/doi/10.2777/1524
European Commission: Directorate-General for Research and Innovation, EOSC Executive Board, Corcho, O., Eriksson, M., Kurowski, K. et al., EOSC interoperability framework – Report from the EOSC Executive Board Working Groups FAIR and Architecture, Publications Office, 2021. https://data.europa.eu/doi/10.2777/620649
FAIR-IMPACT EU (2024, Dec 10) FAIR Implementation Workshop on Repository Trust Resources: Pick & Mix for your Local Needs. YouTube. https://www.youtube.com/watch?v=aqQBY6f9jjs
Foote, K.D (2021, Feb 2). A Brief History of Metadata. Dataversity. https://www.dataversity.net/a-brief-history-of-metadata/
Jenkyns, R., et al. (2025). Guidance on Data Granularity: Report of the RDA Data Granularity WG (Version 1). Zenodo. https://doi.org/10.15497/RDA00126
Lin, D., et al. (2020) The TRUST Principles for digital repositories. Scientific Data 7, 144. https://doi.org/10.1038/s41597-020-0486-7
Riley, J. (2017). Understanding metadata: What is metadata, and what is it for? National Information Standards Organization (NISO), Baltimore. https://www.niso.org/publications/understanding-metadata-2017
Scardaci D.O., et al. (2023). A landscape overview of the EOSC Interoperability Framework – Capabilities and Gaps (Version 1). Zenodo. https://doi.org/10.5281/zenodo.8399710
Verburg, M., et al. (2023). M5.2 – Guidelines for repositories and registries on exposing repository trustworthiness status and FAIR data assessments outcomes (1.0). Zenodo. https://doi.org/10.5281/zenodo.10058634
Wilkinson, M., et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data 3, 160018. https://doi.org/10.1038/sdata.2016.18
Witt, M., et al. (2024). RDA Common Descriptive Attributes of Research Data Repositories (1.0). Zenodo. https://doi.org/10.15497/RDA00103
Wu, M., et al. (2021). Guidelines for publishing structured metadata on the web (3.1). Zenodo. https://doi.org/10.15497/RDA00066
Wu, M., et al. (2024). Ten Principles to Improve Dataset Discoverability (1.0). Research Data Alliance. https://doi.org/10.15497/rda/00120

How to cite this resource
Cortea, I.M. (2025). TRUST-inspiring and FAIR-enabling digital repositories: an implementation story. INFRA-ART Blog. DOI: 10.5281/zenodo.15752934